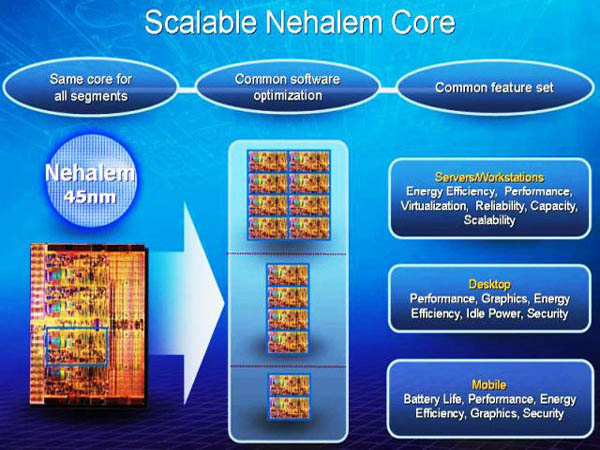
프로세서 (Processor) - 연도별 세대 (Generation) 또는 설계 (Architecture)에 따른 특징들을 소개합니다.
* 상단 브랜드 로고 아이콘을 선택하면 제품 목록과 간단한 사양 정보를 확인하실 수 있습니다.
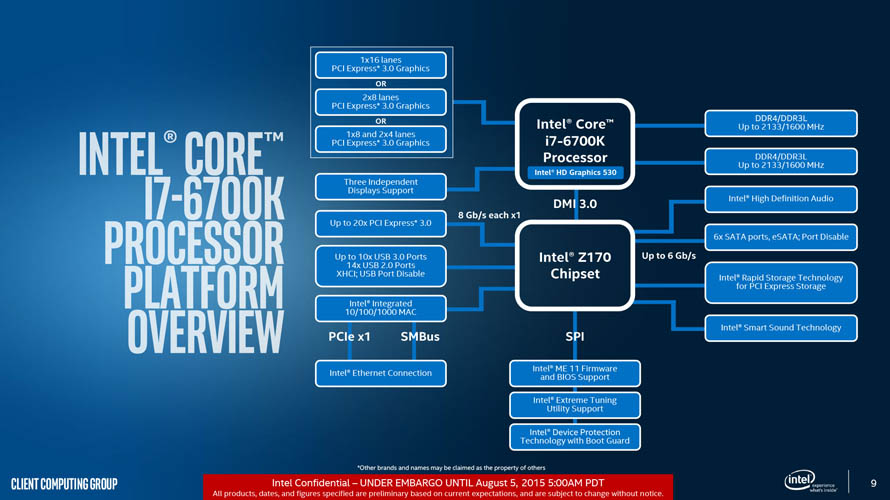
 2018년 10월 (Coffee Lake-S)
2018년 10월 (Coffee Lake-S)
- 9세대 코어 프로세서, 커피 레이크 리프레시

새롭게 신설된 코어 i9 시리즈는 경쟁상대인 라이젠 7 시리즈 대비 확실한 우위를 점하기 위해 8C/16T 구성으로 출시되었으며, 코어 i7 시리즈는 대응 가능한 수준인 8C/8T 구성으로 향상되었습니다. 코어 i5 이하 라인업은 클럭 스피드를 향상시키는 것으로 컨슈머 시장의 왕좌 탈환 및 종합 성능으로도 상대 우위를 가져가며 견제 라인을 구축하는데 성공했습니다.
다만 고클럭 고성능 링버스 설계인 커피레이크 아키텍처 기반 코어가 추가되면서 발열이 큰 폭으로 증가했고, 커피레이크를 생산하는 14nm++ 공정의 출하량이 수요를 따라가지 못해 실질적으로 페이퍼 런칭화 되었다는 평가를 받고 있습니다.
이외에 특기할만한 사항으로는 상승한 발열을 감당하기 위해 실리콘 다이와 히트 스프레더 접합부의 열 전달 물질이 유체 혼합물(Thermal Paste)에서 금속(Indium)으로 바뀌었습니다.

 2018년 8월 (Colfax)
2018년 8월 (Colfax)
- 2세대 라이젠 쓰레드리퍼, 콜팩스

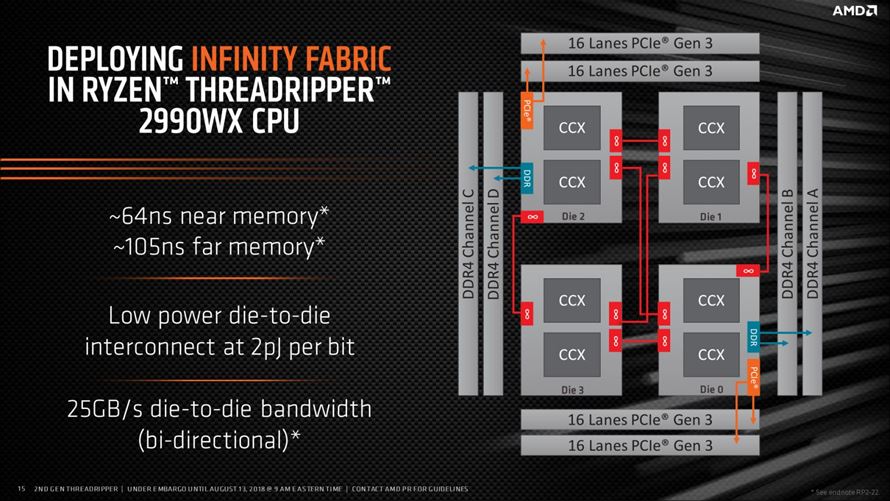
이로써 데스크탑 PC 에서도 서버급 프로세서인 에픽(EPYC)에 버금가는 코어 수를 달성하게 되었지만, 4개의 CCX 패키지 모듈 중 2개는 확장 입출력 인터페이스가 비활성화된 연산 전용 컴퓨트 코어(Compute Core)로 작동하도록 설계해 차별화를 꾀했습니다.

라이젠 쓰레드리퍼 WX 프로세서 시리즈는 32C/64T (2990WX) 모델과 24C/48T (2970WX)로 출시되었습니다. 멀티 코어를 효과적으로 활용하는 어플리케이션에서는 압도적인 성능을 제공하지만 클럭 스피드가 다소 낮은 편이며, 물리적으로 추가된 코어 수 만큼 전력 소비량도 늘어나 메인보드의 부담이 커졌다는 평가를 받고 있습니다.
기존의 라이젠 쓰레드리퍼 X 프로세서의 뒤를 잇는 모델인 2950X는 2개의 CCX 패키지 모듈을 사용하는 16C/32T 구성은 동일하지만, 피나클 릿지의 레이턴시 개선 효과와 약 10% 상승한 클럭 스피드를 바탕으로 향상된 성능을 제공합니다.

2018년 4월 (Pinnacle Ridge)
- 2세대 라이젠 프로세서, 피나클 릿지

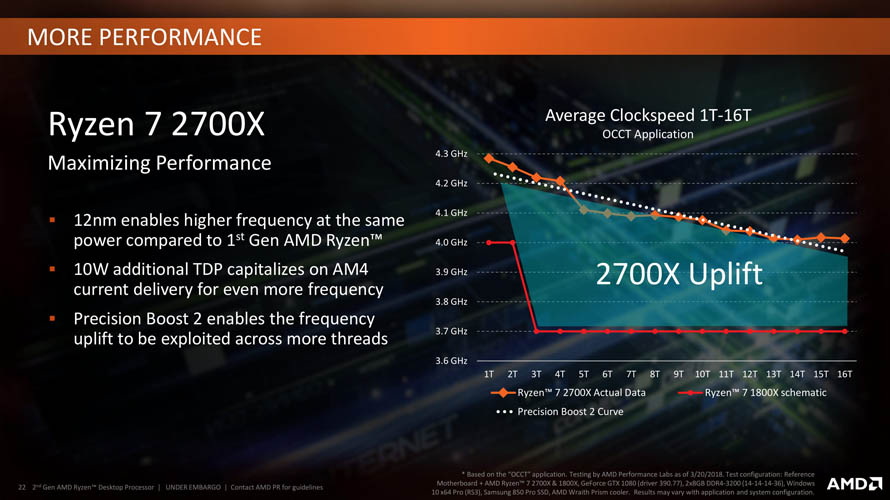
1세대 라이젠의 약점으로 지적되던 캐시 및 메모리 성능이 개선되었습니다. L1 캐시의 반응속도(Latency)를 13%, L2 캐시는 34%, L3 캐시 16% 가량 단축시켜 클럭당 성능(IPC)을 향상시킬 수 있었습니다. 물리적인 설계 디자인 변화는 없었지만 경쟁사의 전략 중 틱(Tick) 또는 최적화(Optimization) 단계에 속하는 세대 교체로 볼 수 있겠습니다.

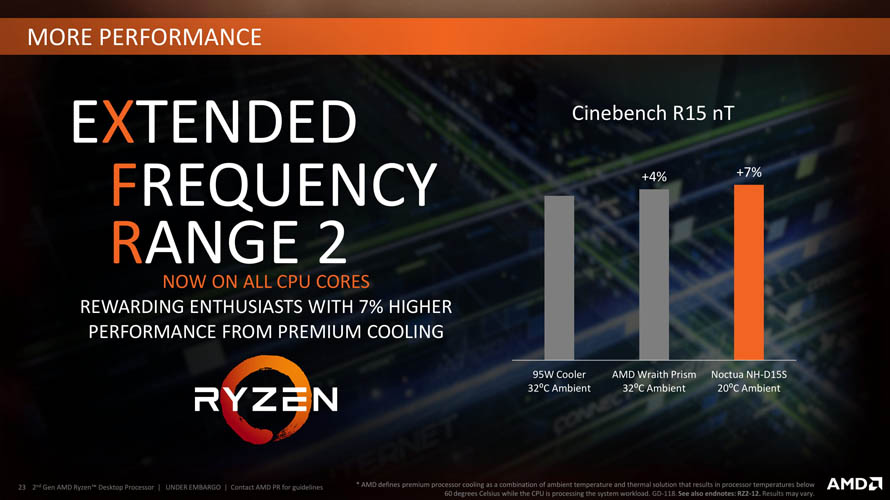
2세대 프리시전 부스트는 이미 레이븐 릿지에서 구현된 알고리즘에 따라 코어/쓰레드 워크로드 수준에 따라 클럭 스피드를 유동적으로 제어할 수 있게 됩니다. 베이스 클럭 / 멀티-코어 부스트 / 싱글-코어 부스트로 경직된 변화만 이루어지던 1세대에 비해 더 효과적인 성능 향상을 제공할 것으로 기대됩니다.
쿨링 솔루션의 성능에 따라 프리시전 부스트 이상의 클럭 스피드로 가속시켜주는 확장 클럭 범위(XFR, eXtended Frequency Range) 기술도 버전업을 거쳤습니다. 1세대 XFR 기술은 엄격한 TDP 제한으로 사실상 수냉에서나 간혹 볼 수 있는 수준에 그쳤지만, 이제는 레이스 맥스(Wraith Max)급 이상의 공냉 쿨러를 사용한다면 충분히 효과를 볼 수 있게 되었습니다.
2018년 2월 (Raven Ridge)
- 1세대 라이젠 G 프로세서, 레이븐 릿지

기존 서밋 릿지의 단일 CCX 모듈에서 L3 캐시를 절반 덜어내는 대신 라데온 RX 베가(Radeon™ RX Vega) 기반의 차세대 컴퓨트 유닛을 최대 11개(704sp)까지 탑재할 수 있는 사양으로 출시되었습니다. 실리콘 다이 상으로는 CCX 모듈과 GPU 모듈이 인피니티 패브릭으로 연결된 형태이며, 이에 따라 CPU 코어는 최대 4C/8T 구성을 취할 수 있습니다.

데스크탑 PC의 경우 고성능으로 갈수록 통합 그래픽 코어보다는 전용 그래픽 카드를 추가로 탑재하는 경우가 많다는 점을 고려해 보급형 라이젠 3 2200G(4C/4T), 중~보급형 라이젠 5 2400G(4C/8T) 모델이 출시되었습니다.
노트북 PC는 일반적으로 업그레이드가 제한적이라는 점을 고려해 가격대 성능비가 우수한 라이젠 5, 고성능 라이젠 7 모델로 출시되었습니다. 두 프로세서 모두 4C/8T 구성이며 클럭 스피드만 0.2GHz 차이를 보입니다. 대신 노트북에서 확보하기 힘든 GPU 코어는 각각 512개(Vega 8), 640개(Vega 10)로 비교적 큰 편이며, CPU와 동일한 클럭 차이도 있어 실질적인 차별화 수단으로 활용되었습니다.
2017년 8월 (Coffee Lake-S)
- 8세대 코어 프로세서, 커피 레이크

커피레이크의 실리콘 다이 면적은 149mm2로 알려져 122mm2의 스카이레이크 / 카비레이크 보다 약 20% 더 커졌습니다. 기본적으로 "코어의 3면을 L3 캐시가 감싸는" 스카이레이크 배치를 그대로 따르고 있으며, 코어 2개가 추가되어 3열로 구성되는 차이가 있습니다. 그 외 I/O 구성, 메모리 컨트롤러, 내장 그래픽 코어 등은 변함 없이 동일합니다.
인텔 8세대 코어 프로세서의 주요 활용처는 게이밍, 컨텐츠 생산, 그리고 오버클러킹입니다. 엔터테인먼트에 특화된 라인업임에도 코어 개수를 50% 늘려 멀티스레드 성능을 대폭 향상시켰을뿐만 아니라, 역대 최고의 싱글-코어 클럭을 달성해 기존 어플리케이션들의 성능도 함께 견인하는데 성공했습니다.
오버클러킹 지원에 관해서는 두 가지 특기할만한 사항이 있는데, 그 동안 메인보드 제조사 차원에서 제공해왔던 개별 코어 오버클럭(Per-core)과 실시간 램타이밍 제어(Real-time Memory Timing)를 공식적으로 지원하게 되었습니다.


2017년 8월 (Whitehaven)
- 1세대 라이젠 쓰레드리퍼, 화이트하벤

물리적으로는 서버용 프로세서인 에픽(EPYC)과 동일하게 4개의 CCX 패키지 모듈을 얹은 모양새지만, 그 중 2개는 생산과정에서 통과하지 못한 실리콘 덩어리입니다. 발열 분산을 위해 덮는 금속 히트-스프레더의 균형을 잡기위해 자리를 채우는 더미(Landfill)로 회로 자체가 연결되지 않기 때문에 유서깊은(?) 코어부활은 불가능합니다.
멀티 칩 모듈(MCM) 패키징으로 설계 난이도를 낮춰 높은 가격대 성능비를 구축했습니다. 일반적으로 프로세서를 MCM 방식으로 설계할 할 경우 코어간 통신을 중계하기 위해 메인보드 칩셋을 경유하는 비효율적인 방법을 사용해야 했지만, AMD는 이러한 패널티를 피하기 위해 인피니티 패브릭(Infinity Fabric)이라는 새로운 허브 인터페이스를 내장해 코어끼리 직접 통신회로를 연결할 수 있도록 설계했습니다.

인피니티 패브릭의 대역폭은 시스템 메모리(DRAM) 클럭과 동기화되는데, 현 시점에서 주력으로 사용되는 DDR4-2400 메모리로는 네이티브 공유 캐시(주로 L3)에 비해 대역폭이나 레이턴시 반응이 다소 부족한 편 입니다. 하지만 특별히 조치를 취하지 않아도 시간이 흐를수록 발전하는 DRAM 기술의 반사이익을 누릴 수 있을 것으로 기대됩니다.

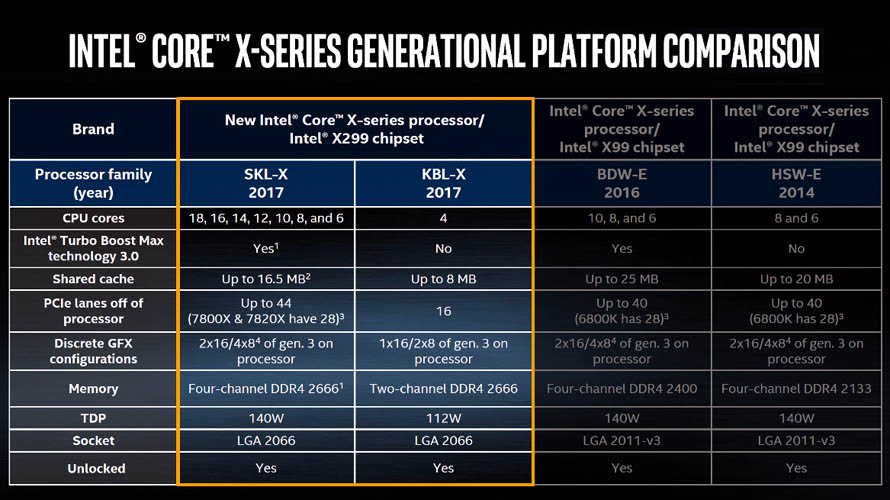
2017년 7월 (Kaby Lake-X)
- 인텔 7세대 코어 X 프로세서, 카비 레이크-X

기존에는 HEDT 라인업도 최상위 제품군을 제외하면 표준 데스크탑과 비슷한 제품관리 규칙(K-SKU)을 쓰고 코드명에 접미사 E(Extreme)를 붙여 구분지었지만, 인텔 코어 X 프로세서부터 모든 HEDT 라인업이 X로 시작되는 코드명과 전용 제품관리 규칙(X-SKU / XE-SKU)을 사용합니다.

각설하고, 코어 X 라인업은 HEDT 시리즈 최초로 베이스가 되는 아키텍처로 두 종류를 동시에 선보였습니다. 그 중에서도 카비레이크-X 기반 제품들은 LGA1151 소켓 규격의 표준 데스크탑 모델보다 더 높은 오버클럭 포텐셜을 추구하는 익스트림 매니아를 위해 LGA2066 소켓 규격에 카비레이크-S 아키텍처를 이식한 사양으로 출시되었습니다.
물론 카비레이크-S 시리즈에 비해 클럭 스피드가 더 높아지고 공식 지원 메모리 클럭도 DDR4-2666으로 상승했지만, 강력한 멀티-쓰레딩 성능을 추구하는 HEDT 라인업의 정체성과는 다소 괴리감이 있는 모델이기도 합니다. 또한 짝을 이루는 메인보드 칩셋(X299)는 기본적으로 상위 아키텍처인 스카이레이크-X를 바탕으로 설계되었기 때문에 카비레이크-X 프로세서를 장착할 경우 일부 메모리 소켓이나 PCI-Express 슬롯을 사용하지 못하는 패널티가 발생합니다.

2017년 6월 (Sky Lake-X)
- 7세대 코어 X 프로세서, 스카이 레이크-X

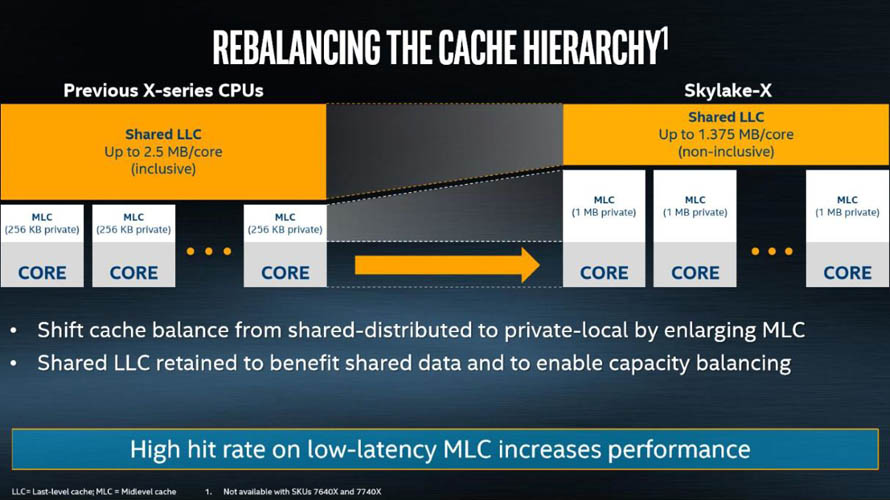
이런 급격한 변화의 일환으로 내부 구조면에서 대대적인 개선이 이루어졌습니다. 약 10년간 유지해오던 링버스(Ringbus) 내부 순환 인터페이스를 그물망(Mesh) 직결 구조로 변경, 코어대 코어간 데이터 공유시 발생하는 지연시간을 최소화 할 수 있도록 했습니다.
언코어 영역에서도 주목할만한 변화가 있었습니다. 그물망 인터페이스 구성으로 인해 공유 캐시(L3)보다 각 코어별 프라이빗 캐시의 비중이 더 커지면서 L2 캐시와 L3 캐시의 리밸런싱이 이루어졌습니다. L2 캐시 크기는 코어 당 1MB로 기존 256KB 대비 400% 증가했고, L3 캐시는 1.375MB로 감소해 55% 수준으로 조정되었습니다. 중간 레벨 캐시 적중률이 증가함에 따라 하위 캐시가 굳이 상위 캐시에 포함된 데이터를 전부 가지고 있을 필요가 없어지면서, 하위 캐시들의 정책 또한 포괄적(Inclusive) 방식에서 배타적(Exclusive) 방식으로 바뀌었습니다.
이외에도 성능 향상을 위한 최적화 기술인 인텔 터보 부스트 맥스 3.0(Intel Turbo Boost Max 3.0)도 강화되었습니다. 이전 세대까지의 터보 부스트 맥스 기술은 싱글-코어 기반 프로그램의 성능을 높이기 위해 가장 뛰어난 컨디션을 가진 코어 하나를 할당해주는 기능이었지만, 스카이레이크-X 기반 프로세서부터 듀얼-코어까지 지원할 수 있도록 개선되었습니다.

2017년 2월 (Summit Ridge)
- 1세대 라이젠 프로세서, 서밋 릿지
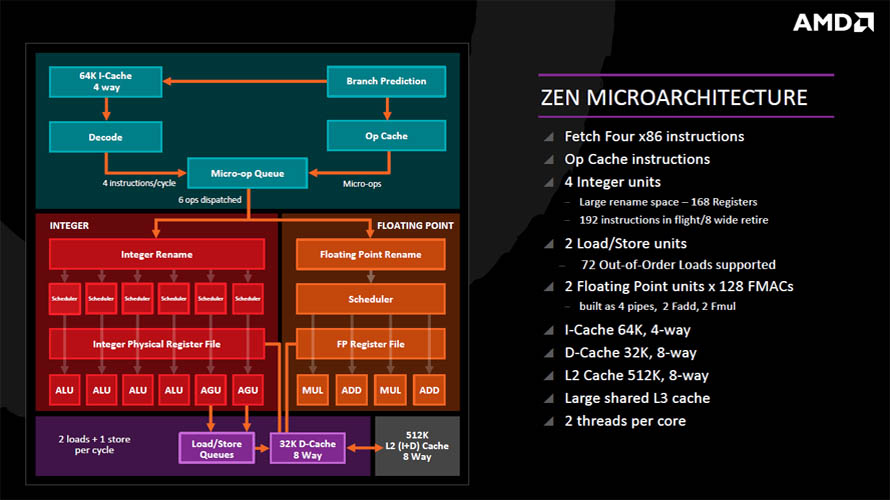
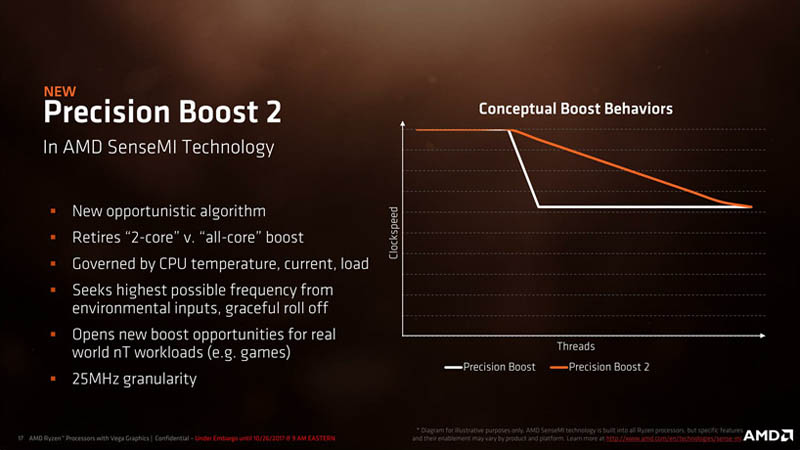
아키텍처 레벨에서 특별히 주목할만한 점은 AMD 프로세서 설계 역사상 처음으로 동시 멀티-스레딩(Simultaneous Multi-threading) 기술을 도입해 1-코어당 2-스레드를 병렬 처리할 수 있게 되었고, 인텔의 마이크로 옵(μOps)에 해당하는 옵 캐시(Ops Cache)를 신설한 덕분에 클럭당 성능(IPC)이 크게 향상되었습니다.
최신 프로세서에서 빠질 수 없는 최적화 동작 알고리즘 역시 AMD SenseMI Technology라는 명칭과 함께 다섯 가지 기능을 강조했습니다.

퓨어 파워(Pure Power) 와 프리시전 부스트(Precision Boost)는 물리적으로 실장된 실시간 전압 / 온도 측정 센서를 활용해 인가되는 전압을 상황에 맞게 조절하거나, 25MHz 단위로 더욱 섬세하게 동작 클럭을 향상시킬 수 있도록 해줍니다. 한편, XFR(eXtended Frequency Range) 기능은 임계 온도가 넘었을 때 베이스 클럭보다 성능을 낮추는 쓰로틀링(Throttling)과 상반되는 개념으로 프로세서가 일정 수준보다 낮은 온도로 동작할 때 프리시전 부스트 시나리오 상의 클럭보다 높은 성능으로 동작하게 됩니다.
신경망 예측(Neural Net Prediction)과 스마트 프리페치(Smart Prefetch)는 명칭(Pre)에도 드러나듯이 연산에 필요한 명령이나 경로를 반복되는 데이터 패턴에서 학습하여 추측, 미리 준비함으로써 더 빠르게 반응할 수 있도록 해줍니다.


2016년 9월 (Bristol Ridge)
- 7세대 APU 프로세서, 브리스톨 릿지

실질적인 연산부(ISA, Instruction Set Architecture) 구조는 이전 세대인 카리조와 동일하지만, 메모리 컨트롤러 차이로 대규모 병렬 실행 및 OpenCL 기반 범용 컴퓨팅 성능이 다소 향상되었습니다. 또한 AVFS(Adaptive Voltage & Frequncy Scaling) 기능을 활용해 실리콘 레벨에서 전압과 클럭의 여유분만큼 가속하되, 신뢰성 추적기(Reliability Tracker)로 안정성을 초과하는 부스팅이 일어나지 않도록 제어합니다.

또한 노트북은 내부 시스템보다 바깥쪽 표면의 온도가 낮다는 점을 활용해 운영체제 부팅이나 어플리케이션 실행 시, 노트북 표면 온도가 임계점에 도달할 때 까지 최대 성능으로 작동하는 STAPM(Skin Temperature Award Power Management) 기능이 도입되었습니다. 일정 온도에 도달하면 표준 성능으로 전환되지만, 그 동안 처리한 데이터만큼 작업량이 줄어들기 때문에 전력 소비량이 소폭 감소하게 됩니다.
이외에도 부팅할 때 마다 자체 구동전압 조정(Boot Time power supply Calibration) 기능을 통해 PC를 사용할 때 마다 실리콘으로 공급되는 전력을 체크해 출하시 상태를 유지할 수 있도록 해줍니다. 전반적으로 모바일 시장에 유용한 기술들이 많이 추가되었으며, 실제로도 가격 경쟁력을 갖춘 노트북 제품이 주를 이루고 데스크탑용 모델은 최소한으로 출시(1개)되었습니다.


2016년 8월 (Kaby Lake-S)
- 7세대 코어 프로세서, 카비 레이크

인텔 7세대 카비레이크 프로세서는 기존에 사용하던 인텔 100 시리즈(Sunrise Point) 메인보드에서도 사용할 수 있지만, 함께 출시된 3DXPoint 기반 SSD 인텔 옵테인(Optane)을 사용하려면 인텔 200 시리즈(Union Point) 메인보드와 함께 사용해야 합니다.

이전 세대인 스카이레이크와 차이점을 꼽자면 공정 최적화에 따라 클럭 스피드가 소폭 상승했으며, 코어 아키텍처 이후 처음으로 펜티엄 시리즈도 하이퍼 스레딩(Hyper Threading) 기술을 지원하기 시작했습니다. 이에 따라 상위 모델인 코어 i3 시리즈는 오버클럭이 가능한 K-SKUs 및 터보 부스트를 지원하는 모델이 추가되었습니다.
또한 연산성능은 비슷하지만 내장 그래픽 코어(iGPU)의 미디어 가속 능력도 여러모로 향상된 모습을 보여줍니다. H.265 및 VP9 고효율 비디오 코덱 기반의 4K / 10bit / 60-fps 영상을 하드웨어 가속 할 수 있으며, H.265 Main 8 / VP9 8bit 인코딩도 하드웨어 가속을 지원합니다. 10bit 컬러를 지원하므로 영상에 HDR 효과를 추가할 수도 있습니다.

2016년 5월 (Broadwell-E)
- 5세대 코어 E 프로세서, 브로드웰-E

하드웨어 트랜잭션 메모리(TSX)를 사용할 수 있도록 개선된 상태로 출시되었기 때문에 데이터베이스 관리 작업에서 더욱 빠른 성능을 기대할 수 있습니다. 이미 세대 교체가 이루어진 하스웰 시리즈는 마이크로코드 업데이트 이후 비활성화 되었고, 브로드웰 역시 초기 스테핑 버전에서 동일한 문제가 발견되었지만 새로운 스테핑 버전으로 정상적으로 작동하도록 수정한 제품을 선보이면서 고성능 멀티스레드 작업에서 차별화된 제품으로 자리잡았습니다.

또한 인텔 터보 부스트 맥스 3.0 기능이 새롭게 추가되었습니다. 싱글-코어 어플리케이션을 실행할 경우 사전에 정의한 베스트 코어를 가속시켜 기존의 터보 부스트 2.0 보다 더 높은 클럭 스피드로 작동합니다. 이로써 표준 데스크탑 모델에 비해 평균적으로 낮은편이던 싱글-쓰레드 성능까지 보완할 수 있게 되었습니다.
DDR4 메모리 가격이 주력 메모리(DDR3)의 두 배에 달하던 하스웰-E 프로세서와 달리, 스카이레이크 덕분에 DDR4 메모리가 주력으로 자리잡은 상황인 브로드웰-E 기반 시스템의 가격은 좀 더 저렴할 법도 했지만 실상은 그렇지 못했습니다. 하스웰-E 프로세서에 비해 5~10% 가량 높은 가격이 책정되었기 때문입니다. 이는 동급 프로세서일 경우 대략 5~10만원 정도이며, 최초의 일반 소비자용 10-코어 프로세서인 i7-6950X Extreme Edition 모델은 8-코어 모델인 i7-6900K 모델보다 $650(65만원 이상) 가량 높은 가격이 책정되었습니다.


2015년 8월 (Sky Lake-S)
- 6세대 코어 프로세서, 스카이 레이크
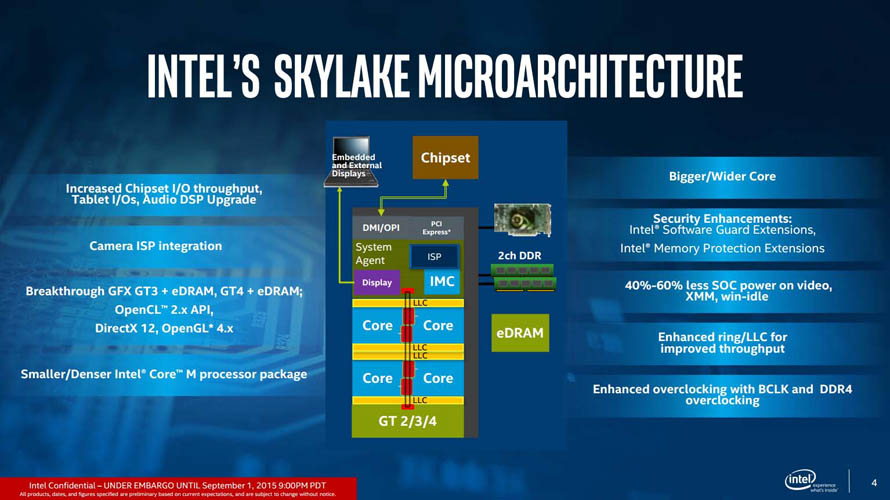
하스웰 아키텍처(4세대)에서 늘린 백엔드에 이어 프론트엔드까지 보강된 스카이레이크는 성능면에서 충분히 긍정적인 요소들을 모두 갖췄습니다. 때마침 메모리 시장도 DDR3 에서 DDR4로 전환되는 시점이었기 때문에 새로운 기왕이면 새로운 시스템으로 전환하는 유저들이 많았다는 점도 스카이레이크의 수요를 늘리는데 한 몫 했습니다.

프로세서와 플랫폼의 경계로 보자면 통합 전압 조정기(FIVR)가 빠지게 되면서 시스템 레벨의 전력 제어권은 메인보드의 역할로 돌아갔습니다. 이는 메인보드들의 품질을 평준화시켰지만, 하이엔드 메인보드의 메리트 감소 및 발열 상승으로 오버클러킹 잠재력을 떨어뜨리던 FIVR의 제약이 사라졌다고 평가할 수 있겠습니다. 인텔의 일반 소비자용 메인보드 플랫폼은 상위 라인업인 Z-Series를 제외하면 오버클럭을 지원하지 않기 때문에 일반 소비자 입장에서는 투자한만큼 돌려받을 가능성이 늘어난 셈 입니다.
이외에도 내장 그래픽 코어의 3D 성능이 제법 향상되었습니다. 이전 세대까지는 저사양 캐주얼 게임으로 분류되던 리그 오브 레전드(LoL)를 쾌적하게 즐기려면 그래픽 옵션의 타협이 필요했지만, 스카이레이크 세대는 코어 i3 부터 풀옵션 상태에서도 쾌적한 플레이가 가능해졌습니다.

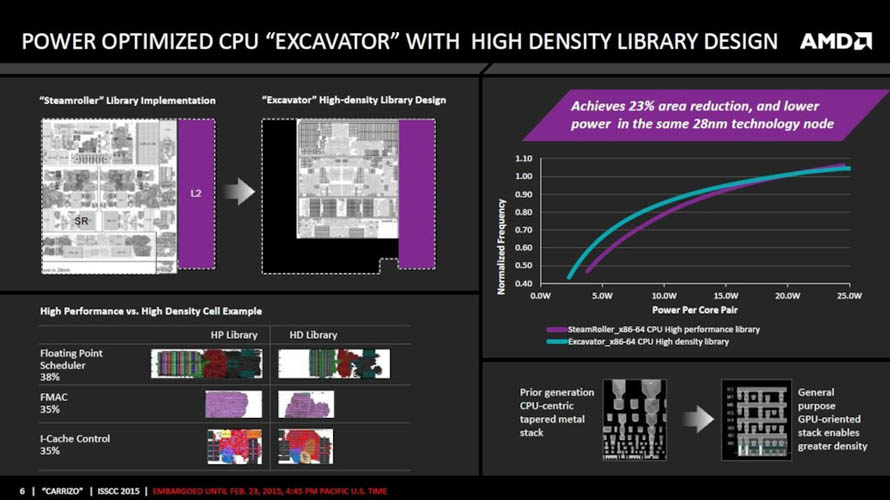
2015년 6월 (Carrizo)
- 6세대 APU 프로세서, 카리조

특히 저전력에서 높은 성능을 낼 수 있도록 설계를 최적화시켜 울트라 모바일 수준인 15W 기준으로 39% 가량 증가한 클럭 스피드를 바탕으로 최대 55%의 성능 향상을 기록했다고 밝혔습니다. 표준 모바일(35W) 전력 환경에서 클럭 스피드 차이는 평균 5% 미만으로 별반 달라지지 않았지만, 약 9~13% 추가로 향상된 성능을 기록해 IPC 증가를 확인할 수 있었습니다.

또한 고밀도 라이브러리 디자인을 채택함에 따라 동일한 28nm 공정임에도 스팀롤러 대비 23%의 면적을 절약해 생산단가를 낮추는 한편, 저전력 상태에서 효율이 높아지는 공정의 특성을 살려 저가형 게이밍 노트북 시장에서 모습을 비추는 일이 늘어났습니다. 특히 모바일에서 중요한 실시간 클럭 및 전압 조절기능을 위해 AVFS 센서 모듈을 내장해 아무런 작업이 없는 대기 상태일 때 절전모드(S3) 수준의 효율을 제공하는 S0i3 기술을 주요 특징으로 내세우기도 했습니다.
CPU 코어를 개선하는데 역량을 집중한만큼 GPU 코어는 카베리와 동일하게 최대 8개(512sp)의 컴퓨트 유닛을 탑재할 수 있도록 설계되었습니다. 점유율 확보가 힘든 데스크탑 PC 시장에는 APU 프로세서 대신 내장 GPU가 빠진 초저가 CPU 형태의 애슬론 X4 835/845 모델들만 출시되었습니다.

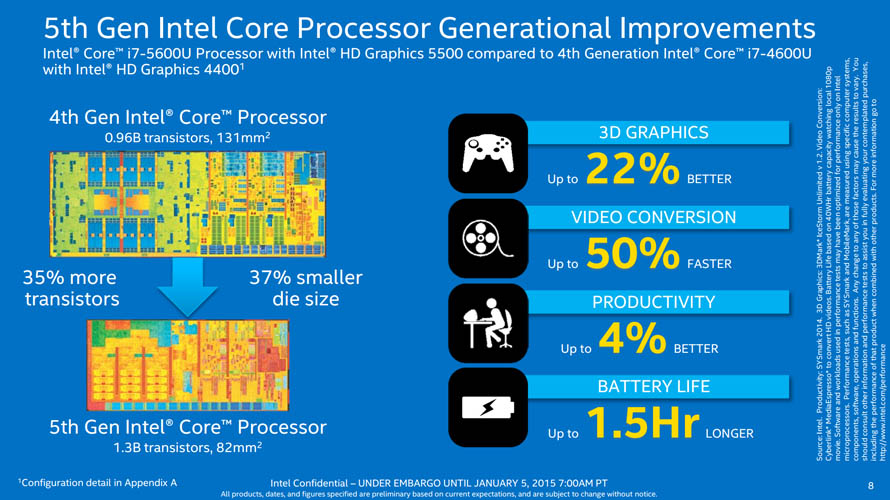
2014년 9월 (Broadwell)
- 5세대 코어 프로세서, 브로드웰

하지만 5세대 기반 리테일 데스크탑 프로세서는 코어 i7-5770C 와 코어 i5-5675C 모델만이 2개월 남짓한 짧은 시간동안 한정적인 수량으로 풀렸습니다. 새로운 기술에도 불구하고 실질적인 연산부인 CPU 코어는 하스웰과 동일한 구조였기 때문에 연산 성능면에서는 큰 차이를 느끼기 힘들었고, 전용 그래픽 카드를 탑재하는 것이 일반적인 고사양 데스크탑 PC 시장에서 내장 GPU 코어 성능이 대폭 향상된 점을 가격 상승폭에 준하는 메리트로 꼽기에는 역부족이라고 보는 시선이 많았습니다.

더군다나 거의 비슷한 시기에 출시된 6세대 스카이레이크 프로세서가 CPU 코어 프론트엔드 확장 + DDR4 메모리 지원 사양으로 출시되었기 때문에, eDRAM 및 TSX 명령어를 기존 플랫폼으로 적극적으로 활용할 계획을 가진 소수의 유저들에게만 공급되고 빠르게 단종 수순을 밟았습니다.
이렇듯 데스크탑 시장에서는 반쯤 의도적으로 징검다리 역할을 수행하게 되었지만, 데스크탑 모델보다 먼저 출시되었던 초박형 노트북 시장에서는 앞서 소개한 모든 특징들이 필수적인 개선 요소로 꼽히는 시장이기 때문에 대대적인 신제품 출시와 함께 세대 교체의 주역으로 대우받았습니다. 특히 2017년 이전까지는 DDR3 메모리가 DDR4 메모리보다 가격대비 용량면에서 앞섰으며, 프로세서 자체 가격대비 성능면에서도 충분한 경쟁력을 갖춘 덕분에 꾸준한 수요를 보이기도 했습니다.
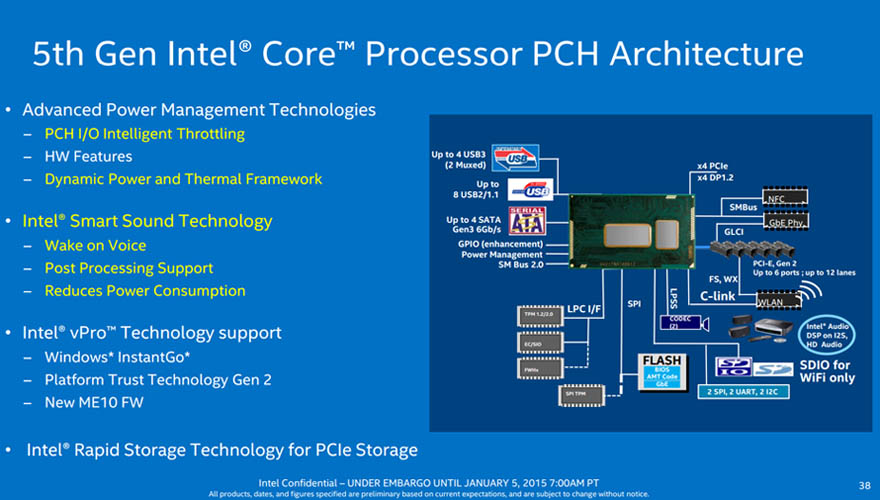
2014년 9월 (Haswell-E)
- 4세대 코어 E 프로세서, 하스웰-E

지난 2/3세대 HEDT 프로세서의 전환이 사실상 공정 전환 정도로 끝난 것이 아쉬웠는지, 이번 세대 교체에서는 최저/최대 코어수를 모두 2개씩 늘려 하이엔드의 이름에 걸맞는 변화를 꾀했습니다.

많은 변화가 있었던만큼 칩셋은 물론이고, 장착하는 소켓까지 전부 새롭게 바뀌었습니다.
그 중 LGA2011-3 소켓의 경우 표준 규격 설계대로의 핀 개수는 2011개지만 CPU 상에 예비로 남겨둔 접점을 포함하면 총 2102개의 핀을 사용할 수 있으며, 일부 메인보드 제조사들은 예비 핀의 일부 또는 전부를 포함시켜 오버클럭에 도움이 될만한 요소를 추가해 OC Socket 등의 명칭으로 제공하기도 합니다.

2014년 1월 (Kaveri)
- 4세대 APU 프로세서, 카베리

개선된 CPU 코어인 스팀롤러(Steamroller)는 이전 세대인 불도저나 파일드라이버 기반 아키텍처에서 사용되던 1개의 공유 명령어 디코더 유닛을 2개의 개별 유닛으로 분산 배치해 병목현상을 해소하는 한편, 분기 예측 강화로 캐시 미스를 줄여 가장 큰 문제인 코어당 성능(IPC)을 10-20% 가량 향상시키는데 성공했습니다.
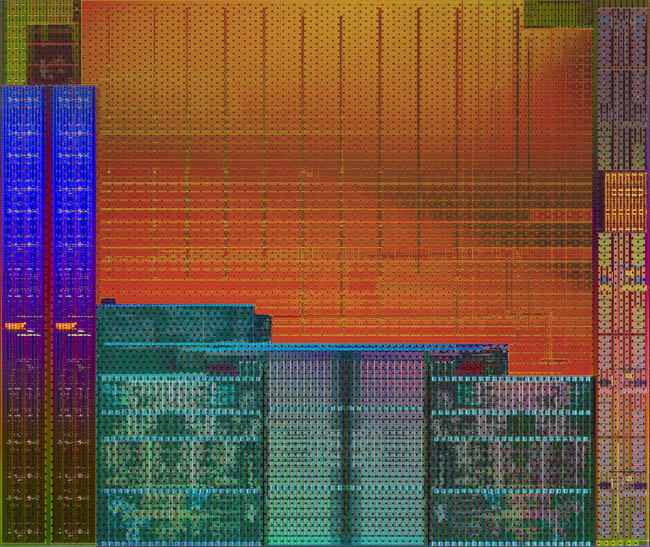
GPU 코어는 최신 그래픽 카드인 라데온 R9 290X(Hawaii) 기반 컴퓨트 유닛을 최대 8개(512sp)까지 탑재할 수 있도록 디자인 되었습니다. 테라스케일(VLIW) 기반의 이전 세대 APU들에 비해 범용 GPU 명령어(OpenCL 등) 활용을 더 쉽고 강력한 성능으로 만들어줍니다.

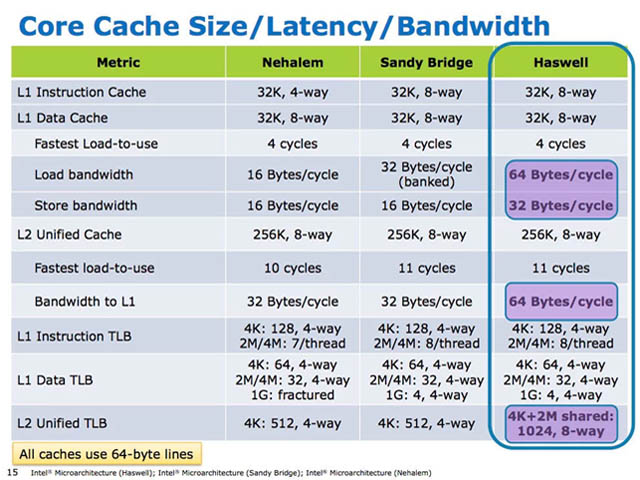
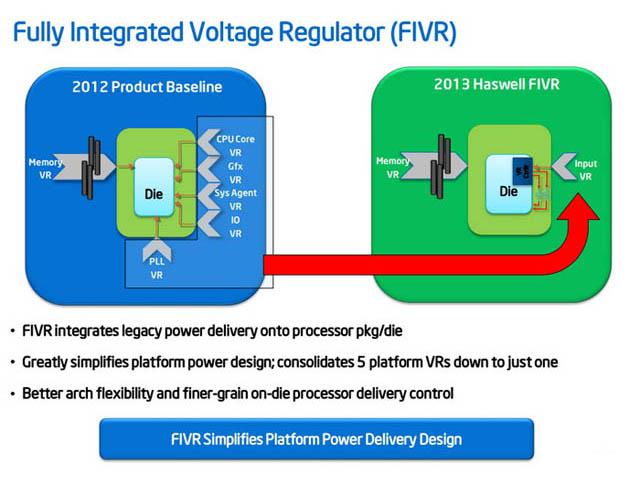
2013년 6월 (Haswell)
- 4세대 코어 프로세서, 하스웰
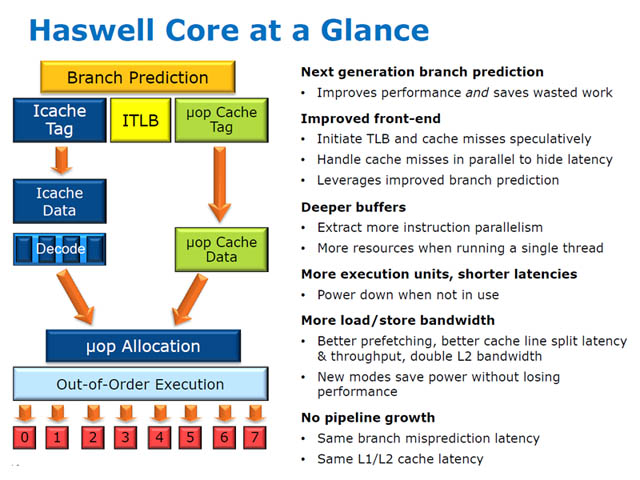
프로세서에 내장되는 통합 전압 조정기(FIVR)를 채택해 클럭 변동에 따른 전압 조절을 더 정밀하고 빠르게 제어할 수 있게 되었습니다. 메인보드의 경우 저가형 제품의 전력 설계에 별다른 노력을 들일 필요가 없어졌지만, 고가의 메인보드에서 제공하던 고급 전력 제어기능도 유명무실해지는 현상이 부각되기도 했습니다.
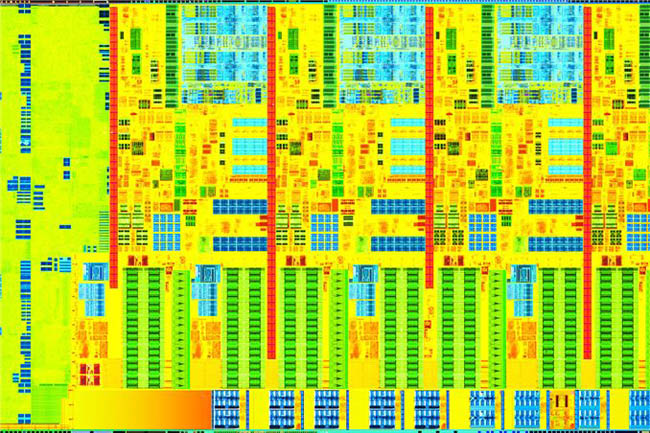
2014년에는 후속 공정인 14nm 생산이 연기되어 클럭 스피드를 좀 더 높인 하스웰-리프레시와 데빌스 캐년(Devil's Canyon) 라인업을 출시했습니다. 인텔의 프로세서 역사상 최초로 베이스 클럭 4.0GHz로 작동하는 코어 i7-4790K와 펜티엄 브랜드가 20주년을 맞이한 기념으로 유일한 오버클럭 지원 모델인 펜티엄 G3258이 함께 출시되었습니다.
2013년 9월 (Ivy Bridge-E)
- 3세대 코어 E 프로세서, 아이비 브릿지-E

대신 더욱 미세해진 22nm 공정이 적용되어 클럭 스피드가 상승했으며, 미세 공정으로 늘어난 클럭 여유폭을 십분 활용해 배수(Ratio) 조절을 최대 63x 까지 설정할 수 있습니다. 물론 어디까지나 설정이 가능할 뿐이고 정상작동 수치를 찾는 일은 오버클러커의 역할입니다.
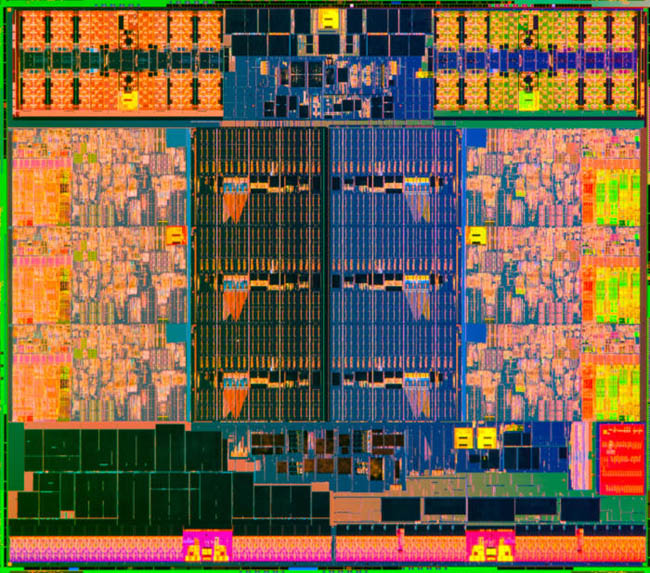
또한 PCI-Express 3.0 인터페이스를 지원해 장치(특히 그래픽 카드) 간 대역폭이 두 배로 상승했습니다. 짝을 이루는 메인보드 칩셋은 샌디 브릿지-E와 동일한 X79이지만, 프로세서와 직결된 슬롯은 PCI-Express 3.0 규격으로 동작합니다. 단, 칩셋간 인터페이스는 여전히 DMI 2.0을 사용하기 때문에 X79 칩셋과 연결된 슬롯은 여전히 PCI-Express 2.0 규격으로 동작합니다.


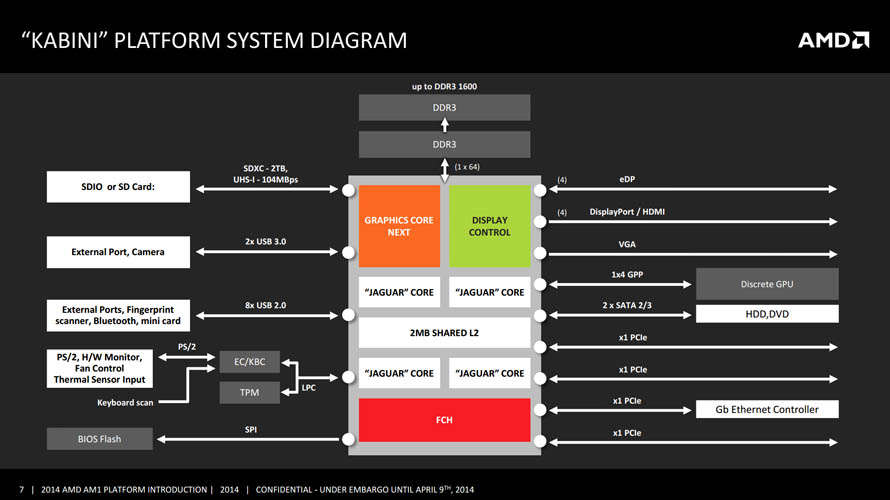
2013년 5월 (Kabini)
- 3세대 APU 프로세서, 카비니

CPU 코어인 재규어는 최신 게임콘솔인 PS4 와 Xbox One 에 탑재된 것으로 유명합니다. 비록 데스크탑 PC 시장에서는 기를 못펴고 있지만 넷북/넷탑 및 임베디드 시장에서 호평을 받았던 밥캣(Bobcat) 코어에서 한층 더 진보한 설계로, 단일코어 위주로 설계뙨 밥캣이 듀얼코어에 머무른 것과 달리 재규어는 처음부터 쿼드코어 기반으로 설계되었기 때문에 다중작업이나 멀티쓰레드 작업에 더 유리해졌습니다.

또한 AMD가 제공할 수 있는 메리트 중 하나인 GPU 코어는 라데온 R7 260과 동등한 기술 구현이 가능한 GCN 설계에 기반하고 있습니다. 통합 비디오 디코더(UVD)를 내장하고 있어 코덱에 따라 4K UHD 영상도 끊김없이 재생할 수 있고, 가벼운 3D 그래픽 구현에도 경쟁사에 비해 더 나은 품질과 성능을 제공합니다. 이러한 장점들은 어린이를 위한 가벼운 캐주얼 게임부터 가정용 홈시어터(HTPC) 플랫폼으로 활용하기에 충분한 매력이 될 수 있습니다.
마지막으로 카비니는 시스템 온 칩(SoC) 구조로 CPU 와 GPU 코어는 물론이고 SATA 나 USB 포트와 같은 입출력 칩셋 기능까지 프로세서에 통합되어 있습니다. 따라서 메인보드에 브릿지 칩셋을 장착할 필요가 없어 성능, 전력, 면적 등 여러 측면에서 소형 폼팩터에 최적화된 구성을 갖췄다고 평가할 수 있겠습니다.
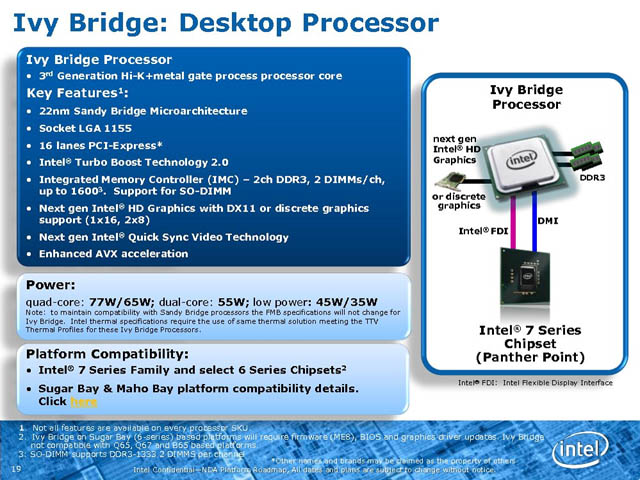
2012년 4월 (Ivy Bridge)
- 3세대 코어 프로세서, 아이비 브릿지

프로세서 레벨에서는 대역폭이 두 배로 늘어난 PCI-Express 3.0 인터페이스가 최초로 적용되기 시작했으며, 짝을 맞춰 출시된 인텔 7-시리즈 칩셋 플랫폼도 마찬가지로 대역폭을 늘린 SATA3 인터페이스(6Gb/s)가 최초로 적용되었습니다.

공정 전환으로 발열이나 전력에서 이점이 있을 것으로 기대되었지만, 히트-스프레더와 코어 사이의 열 전달 물질이 TIM(Thermal Interface Material)으로 변경되면서 데스크탑 시장에서는 온도 측면에서는 부정적인 시선이 많습니다. 모바일 프로세서는 실리콘 다이가 노출된 형태로 출고되기 때문에 샌디브릿지에 비해 여러 측면에서 개선되었다는 평가를 받았습니다.
2012년 10월 (Vishera)
- 2세대 FX 프로세서, 비쉐라
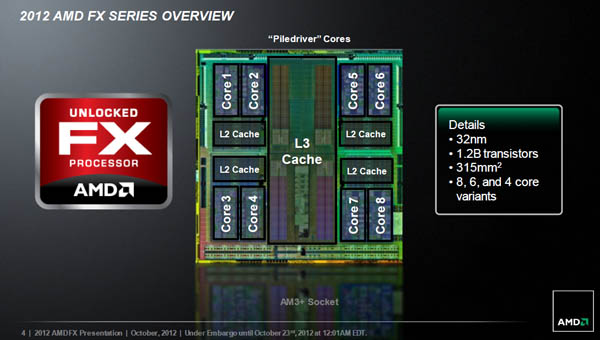
위와 같은 변화를 통해 이전 세대 아키텍처보다 떨어지는 성능은 만회했지만, 경쟁사 제품과 성능 격차는 여전했기 때문에 비판을 피해갈 수 없었습니다. 특히 클럭을 향상시켜 성능을 만회할 수 있도록 개방한 오버클럭(Unlocked) 정책은 함께 제공되는 정품 쿨러로는 발열을 감당하지 못하거나 소음이 급격하게 증가하는 문제로 몸살을 앓았고, 덩달아 상승한 전력 소비량 역시 감당하지 못하는 메인보드들이 발견되어 가격적인 메리트가 희석되는 경향을 보였습니다.

이후 AMD는 오랫동안 중장비 코드명을 갖는 프로세서의 고성능화를 잠정 중단하고, 차기 아키텍처가 완성될 때까지 고효율 저전력화를 통한 메인스트림 프로세서 개발 및 주문제작형 SoC 설계에 주력하는 방향으로 전환했습니다.
2017년 후속 마이크로 아키텍처인 젠(Zen) 코어가 출시되면서 시장을 넘겨주게 되었는데, 아이러니하게도 출시되었을 당시에는 빛을 보지 못했던 모듈식 멀티코어가 충분히 활용될 수 있는 방향으로 소프트웨어 시장의 발전이 이루어져 뒤늦게 경쟁력을 갖춘 가격대비 성능으로 재평가되기도 했습니다.
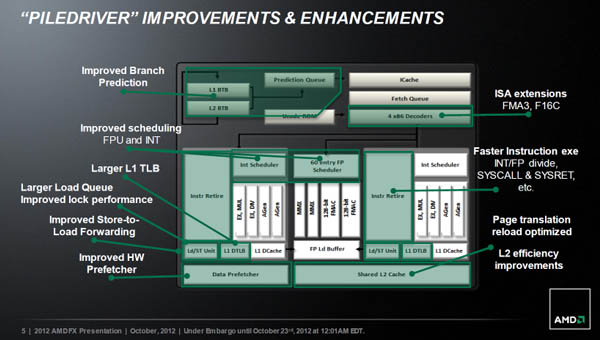
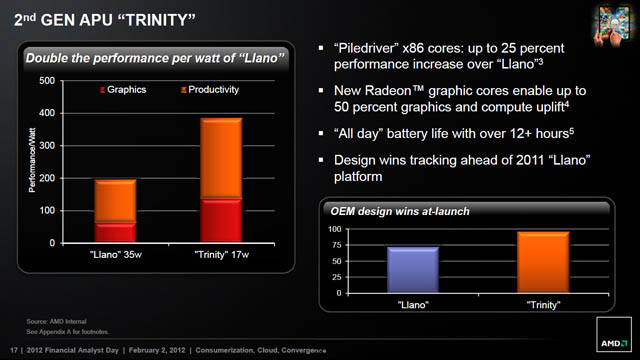
2012년 5월 (Trinity)
- 2세대 APU 프로세서, 트리니티

트리니티에 사용된 파일드라이버(Piledriver) CPU 코어는 라노에 적용되었던 스타즈(Stars) 코어는 물론이고, 현행 아키텍처의 원형인 불도저(Bulldozer)에서도 한 차례 개선되어 저전력 멀티 프로세싱을 구현했습니다. 3세대 테라스케일 GPU 코어 역시 라노의 2세대 테라스케일에 비해 효율성을 강화시킨 구성으로 더 작은 실리콘 다이로도 동급의 성능을 낼 수 있도록 개발된 모델입니다. 덕분에 트리니티는 라노에 비해 64개 더 많은 스트림 프로세서(SP)를 내장할 수 있게 되었습니다.

고효율 아키텍처 설계에 따라 AMD는 트리니티는 1세대 APU에 비해 전력당 성능비가 최대 2배까지 향상되었다고 주장했습니다. 특히 지금까지 AMD 라인업에 존재하지 않던 17W 급의 초저전력 모델이 추가되는 등, 기존의 저가형 데스크탑 시장 확보에 이어서 노트북 시장에서도 가격대 성능비를 위시한 전략을 펼칠 것으로 보입니다.
2011년 11월 (Sandy Bridge-E)
- 2세대 코어 E 프로세서, 샌디 브릿지-E
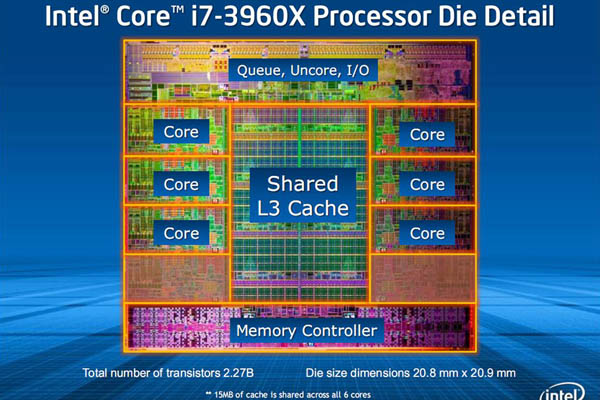
코어 및 공유 캐시 활성화 정도에 따라 4-코어 10MB 공유 캐시(i7-3820)와 6-코어 12MB 공유 캐시(i7-3930K), 6-코어 15MB 공유 캐시(i7-3960X)로 총 3개 모델이 출시되었습니다.

최대 3-채널 메모리를 지원하던 네할렘 & 웨스트미어 기반의 일반 소비자용 1세대 코어 아키텍처에서 더 나아가 4-채널 메모리를 지원해 더욱 넓어진 대역폭을 갖추게 되었습니다. 메모리 대역폭 자체는 일반적인 컴퓨팅 성능에 큰 영향을 미치지 않지만, 더 많은 메모리를 장착할 수 있어 쾌적한 성능을 자랑하는 PC 구축이 가능해졌습니다.


2011년 6월 (Llano)
- 1세대 APU 프로세서, 라노 (Llano)

AMD가 꿈꾸는 이상적인 APU를 향한 첫 단계로 CPU 코어와 GPU 코어가 하나의 실리콘 다이에 통합되었으며, 내부적으로 Fusion Compute Link(Onion)와 Radeon Memory Bus(Garlic)로 명명된 전용 인터페이스로 연결되었다는 점에서 의의를 갖는 제품입니다.

CPU 코어는 1세대 FX 시리즈에 사용된 불도저가 아닌 페넘 II 시리즈의 스타즈(Stars) 마이크로 아키텍처의 공정 미세화 버전이 적용되었고, GPU 코어는 라데온 HD 5000 시리즈에 사용된 2세대 테라스케일(Terascale) 아키텍처가 사용되었습니다. 두 아키텍처 모두 최신 사양은 아니지만, 나름대로 출중한 가격대 성능비로 인기를 얻었던 모델들이었기 때문에 라노 역시 호평을 받았습니다.
특히 비슷한 형태(CPU+GPU)의 경쟁사 프로세서에 비해 CPU 성능은 조금 부족하지만 GPU 성능이 압도적으로 뛰어났고, 가격 또한 상당히 저렴했기 때문에 전용 그래픽 카드 추가가 힘든 저가형 PC 견적으로 많이 채택되었습니다.

2011년 10월 (Zambezi)
- 1세대 FX 프로세서, 잠베지

그러나 실상은 공유되는 부동 소수점 연산기가 처리량에 따라 유연하게 분배되는 방식이 아니라, 엄격하게 정의된 사이클마다 분배가 이루어지기 때문에 쓰레드 하나 당 절반의 자원밖에 활용할 수 없어 성능이 크게 떨어지는 것으로 나타났습니다. 특히 멀티-코어 프로세서를 사용하는 이유가 멀티-쓰레드 어플리케이션의 성능 향상보다 다수의 싱글-쓰레드 프로그램을 실행시키더라도 여유로운 프로세서 자원으로 쾌적한 멀티 태스킹을 할 수 있다는 점이 더 주요한 시기였기 때문에 AMD의 예상을 웃도는 문제로 떠올랐습니다.

결과적으로 잠베지는 멀티-쓰레드를 제대로 활용하지 않는 대다수 어플리케이션에서 라이벌로 여겼던 샌디 브릿지는 커녕, 이전 세대인 스타즈 마이크로 아키텍처보다 클럭당 성능(IPC)이 떨어지는 웃지못할 성적표를 받아들어야 했습니다.


2011년 1월 (Sandy Bridge)
- 2세대 코어 프로세서, 샌디 브릿지
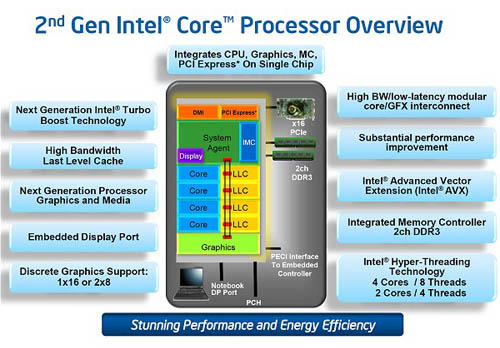
아키텍처 측면 외에도 새로운 확장 명령어 세트나 부가 기능 개선을 통해 성능 향상을 꾀했습니다. 고급 벡터 확장(AVX, Advanced Vector eXtension)은 x86 프로세서의 극적인 성능 향상을 가능케했던 MMX와 SSE의 뒤를 잇는 확장 명령어 세트로, 기존의 128-bit/2-OPrd(SSE)에서 256-bit/3-OPrd로 개선되어 약 2.5배에 달하는 성능을 낼 수 있습니다.
인텔 터보 부스트 기능도 2세대로 진화하면서 좀 더 적극적으로 성능을 높일 수 있도록 개선되었습니다.
터보 부스트 1.0은 열설계전력(TDP)을 비교적 엄격하게 지켰기 때문에 클럭 상승폭이나 유지 시간이 여유롭지 않았지만, 터보 부스트 2.0부터는 안전한 시간 내에서 TDP를 넘는 클럭 스피드를 유지한 뒤 안정 상태로 복귀하도록 바뀌었습니다. IDF에서 공개한 자료에 의하면 약 25초 가량 TDP 초과 상태를 안전하게 유지할 수 있다고 합니다.
2010년 1월 (Westmere)
- 1세대 코어(32nm) 프로세서, 웨스트미어 (Westmere)

한편, 보급형 모델은 클락데일(Clarkdale)이라는 코드명으로 듀얼-코어 CPU와 GPU가 통합된 형태로 출시되었습니다. CPU 코어는 32nm 공정이지만 메모리 컨트롤러와 GPU 코어는 45nm 공정으로 생산되어 별도의 실리콘 다이를 갖췄으며, 이를 하나의 PCB 기판에 멀티 칩 모듈(MCM) 방식으로 얹은 형태입니다.
메모리 컨트롤러가 외부 인터페이스로 연결되어 실질적인 성능은 감소했기 때문에 코어i5/i3 이하의 보급형 모델로 출시되었습니다.

기존의 린필드 제품군과 겹치는 구간인 인텔 코어 i5 프로세서 시리즈의 경우 린필드 기반 4C/4T 제품군은 코어 i5-700, 클락데일 기반 2C/4T 제품군은 코어 i5-600으로 나뉘어 어렵지 않게 구분할 수 있도록 구성되었습니다.


2008년 11월 (Nehalem)
- 1세대 코어(45nm) 프로세서, 네할렘

시간이 조금 흐른 뒤에는 중급형 시장을 위해 LGA1156 소켓과 함께 린필드(Lynnfield) 시리즈를 출시했습니다. LGA1366에 비하면 메모리 컨트롤러의 성능이 조금 축소되어 2-채널만 지원하며, DDR3 메모리 공식 지원 대역폭도 소폭 낮아졌습니다. 또한 프로세서와 칩셋간의 연결 방식도 QPI 대신 기존의 다이렉트 미디어 인터페이스(DMI, Direct Media Interface)를 채택했습니다. 그럼에도 불구하고 프로세서 성능 자체는 블룸필드에 필적했기 때문에 상당한 인기를 누렸습니다.